

Table of Links
-
Experiments
4 Experiments
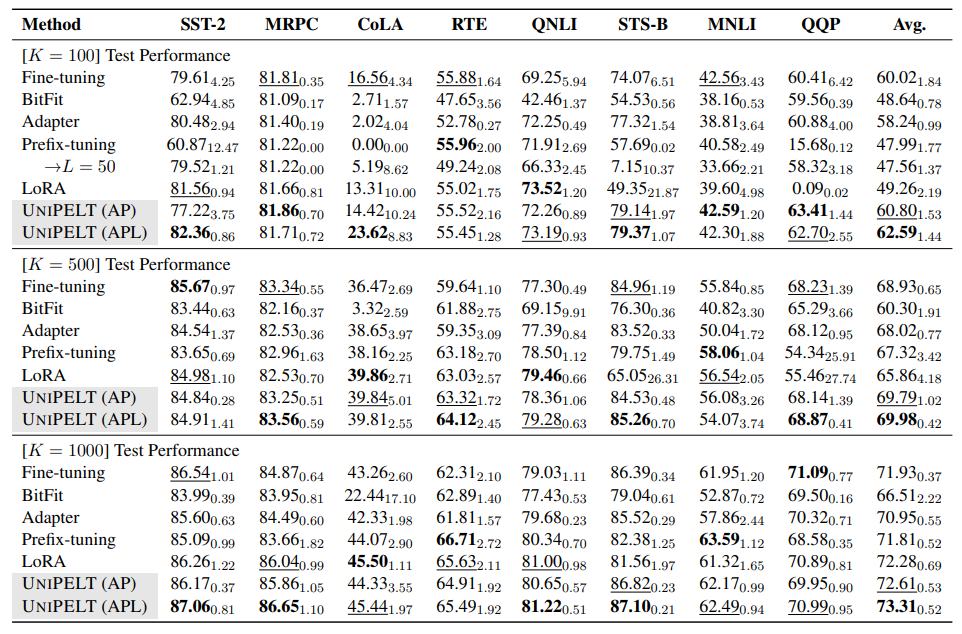
We conduct extensive experiments with 8 tasks × 4 data sizes × 7 methods × 5 runs per setup, along with additional analysis for particular methods, resulting in 1,000+ runs in total.
4.1 Experiment Setup
Task Setup. We conduct experiments on the General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2019), which involves four types of natural language understanding tasks including linguistic acceptability (CoLA), sentiment analysis (SST-2), similarity and paraphrase tasks (MRPC, STS-B, QQP), and natural language inference (MNLI, QNLI, RTE). We exclude the WNLI dataset following prior studies (Houlsby et al., 2019; Devlin et al., 2019).
Data Setup. We mainly consider a low-resource setting where training data is limited and the performance of different methods varies much. We sample a small subset of the training set for each task with size K = {100, 500, 1000}. As it is infeasible to submit considerable runs to the GLUE
leaderboard (2 submissions/day), we take 1,000 samples on the training set as the development set to select the best checkpoint and use the original development set as the test set. To reduce variance, we shuffle the data with 5 random seeds and report the average performance. Additionally, we consider a high-resource setting where the whole training set is used and the best performance on the GLUE development set is reported.
Compared Methods. We mainly compare UNIPELT with fine-tuning and four representative PELT methods: adapter (Houlsby et al., 2019), prefix-tuning (Li and Liang, 2021), BitFit (Ben Zaken et al., 2021), and LoRA (Hu et al., 2021). For completeness, we consider two model variants UNIPELT (AP) and UNIPELT (APL), which incorporate 2 and 3 PELT methods, respectively.

4.2 Analysis of Individual PELT Methods
In Table 1, we show the performance of different methods on the GLUE benchmark with various sizes of training data. The results on the development sets are generally consistent with the test sets and provided in App. D. Although the average performance of different methods over 8 tasks is sometimes similar, the differences between tasks are quite significant under certain setups and can be as large as 5~9 points on a specific task (e.g., STS-B and MNLI, K = 500) even when excluding cases where some methods fail to learn effectively (e.g., prefix-tuning on QQP, K = 100).
Next, we will analyze and examine each individual PELT method more closely.


On the other hand, there are certain tasks (e.g., STS-B) that adapter largely outperforms competitive methods such as prefix-tuning and LoRA regardless of the size of training data, suggesting that one should favor adapter over other PELT methods under certain scenarios as well.
Analysis of Prefix-tuning. Prefix-tuning performs poorly with K = {100, 500} and becomes on par with fine-tuning when K reaches 1000. We also observe that prefix-tuning fails to learn effectively on certain tasks when the training data is limited (e.g., K = 100 on SST-2 and K = 500 on QQP), leading to unsatisfactory performance and (or) large variance across different runs. Similar phenomena have been observed in a concurrent study (Gu et al., 2021) on few-shot prompt-tuning.
To ensure that the poor performance of prefixtuning is not due to its fewer trainable parameters (based on its default setting), we further increase the prefix length to L = 50 such that its trainable parameters are comparable to adapter, and reevaluate prefix-tuning on all 8 tasks with K = 100. For the 4 tasks where prefix-tuning (L = 10) performs poorly (SST2, CoLA, STS-B, and QQP), while its performance is significantly improved on 3 tasks, it also performs significantly worse on the other task (STS-B), which suggests that training instability in the low-resource regime is still an issue for prefix-tuning even with more trainable parameters.[5] Besides, prefix-tuning (L = 50) still lags behind adapter or UNIPELT (AP) on 3 of the 4 tasks. Furthermore, the average performance of prefix-tuning (L = 50) on 8 tasks is even slightly worse than with L = 10, which indicates that increasing prefix length may not be a panacea for all the scenarios. A larger L also leads to significant training/inference slowdown due to the costly multi-head attention. More broadly, such results suggest that using more trainable parameters does not guarantee better performance.
On the bright side, prefix-tuning performs well on certain tasks such as natural language inference (RTE and MNLI) with various sizes of training data, which suggests that one should also prefer prefix-tuning in certain cases.
Analysis of BitFit & LoRA. Tuning only the bias terms of the model does not lead to very satisfactory results in our experiments – BitFit never performs the best and generally performs the worst in different data and task setups. Therefore, we do not consider BitFit in the following experiments and exclude BitFit as a submodule of UNIPELT. As for LoRA, there are a few setups where LoRA fails to learn effectively as well, such as STS-B and QQP (K = {100, 500}), leading to high variance across runs. Apart from that, LoRA performs
quite competitively despite using fewer trainable parameters than methods like adapter, especially when K = 1000, achieving the best or 2nd best performance on 4 of 8 tasks.
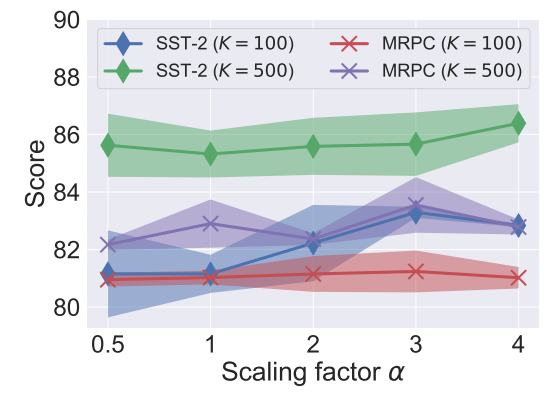
As LoRA has a scaling factor α that can be seen as a static gating function under our formulation, we further investigate its importance by evaluating LoRA with different α. As shown in Fig. 3, LoRA is quite sensitive to the scaling factor and there seems to be no single optimal value that works well across multiple task and data setups. Such findings suggest that gating is critical and motivate us to use more fine-grained and dynamic control for UNIPELT. Besides, we observe that increasing α consistently results in faster convergence, possibly because the trainable parameters would receive larger gradient updates with a larger α.
4.3 Analysis of UNIPELT
Next, we will turn to our proposed framework UNIPELT, which incorporates multiple existing PELT methods as submodules.
Low-Resource Performance. Overall, UNIPELT (APL) and UNIPELT (AP) consistently achieve the best and second best average performance on both the development and test sets regardless of the number of training samples. The gains are generally 1~4% over the submodule that performs the best (when used individually). Such results demonstrate the advantages of our hybrid approach regarding model effectiveness and generalizability.
At the per-task level, UNIPELT (APL) and UNIPELT (AP) perform the best or second best on 7/6/7 of 8 tasks when trained with 100/500/1,000 samples, and never perform the worst in any setup. When comparing the two variants, UNIPELT (APL) outperforms UNIPELT (AP) on 4/6/8 of 8 tasks when trained with 100/500/1,000 samples. Such results indicate that UNIPELT is quite robust and performs reliably under different scenarios. The improvements of UNIPELT over its submodules are generally larger when having fewer training samples, suggesting that UNIPELT performs especially well in the low-resource regime. In particular, on the tasks where other PELT methods fail to learn effectively such as CoLA and QQP (K = 100), UNIPELT manages to achieve performance better than fine-tuning.
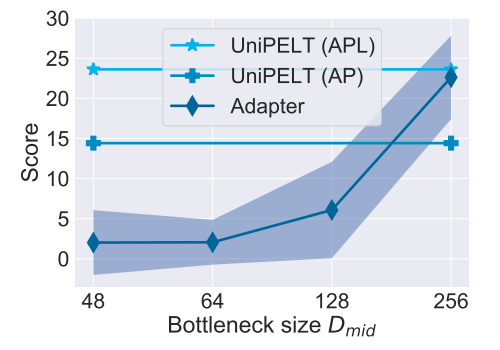
UNIPELT vs. Upper Bound. In Table 2, we show the comparison of UNIPELT and the upper bound that takes the best performance of its submodules on each task. We observe that both UNIPELT (AP) and UNIPELT (APL) perform similarly or even better than their upper bound, which suggests that UNIPELT successfully learns to leverage different submodules and maintains (near) optimal performance under different setups. The fact that UNIPELT can outperform the upper bound also hints that a mixture of PELT methods (involving different parts of the PLM) might be inherently more effective than single methods (with a limited scope of the PLM architecture).
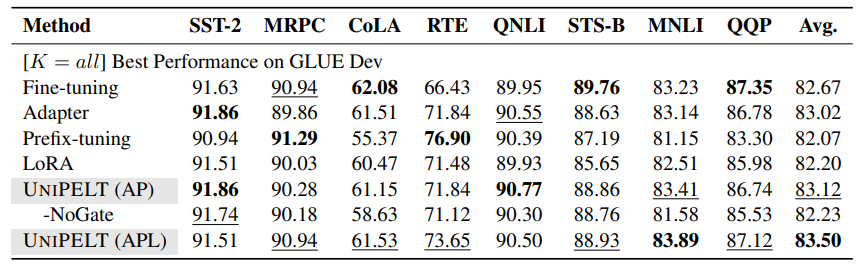
High-Resource Performance. In Table 3, we list the performance of different methods when all training samples are used. UNIPELT again achieves the best overall performance. The gains are not as significant as in the low-resource setting, which is somewhat expected as existing PELT methods typically perform on par with fine-tuning given abundant training data and the potential of improvement is not as high. That said, the performance of UNIPELT is still the best or 2nd best on all 8 tasks, and generally comparable to the best submodule used individually on each task. Besides, simply combining multiple PELT methods without gating does not work well in the high-resource setting – although UNIPELT-NoGate never performs the worst in each task, its average performance is unsatisfactory (-0.89 vs. UNIPELT).
4.4 Efficiency of PELT Methods
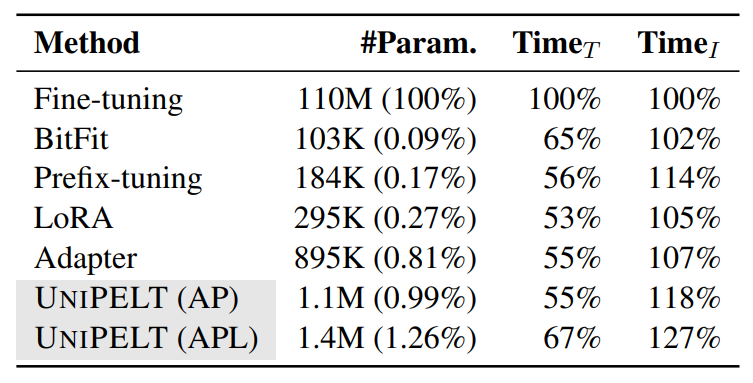
We benchmark the efficiency of PELT methods and list in Table 4 their number of trainable parameters and training/inference time relative to fine-tuning.
Parameter Efficiency. As the trainable parameters in PELT methods are almost negligible, combining multiple methods does not lead to significant losses in parameter efficiency. UNIPELT still has few trainable parameters compared to fine-tuning (0.99%~1.26%). The parameters can be further reduced if one uses more parameter-efficient variants (e.g., Karimi Mahabadi et al. (2021a)), which can be easily swapped with the vanilla version used in our current framework. Also, note that more trainable parameters do not always lead to better performance, as shown in our experiments and prior studies (He et al., 2021; Pfeiffer et al., 2021).
Training and Inference Efficiency. Due to parameter efficiency, all PELT methods train 30%~50% faster than fine-tuning and incorporating multiple PELT methods into UNIPELT does not suffer from slower training. On the other hand, the inference time of PELT methods is generally longer since they involve more FLOPs. UNIPELT has a slightly larger inference overhead (4%~11% compared to its slowest submodule), which we argue is insignificant since larger models that may achieve similar performance gains (e.g., BERTlarge) need around 300% inference time (Wolf et al., 2020).
Authors:
(1) Yuning Mao, University of Illinois Urbana-Champaign and the work was done during internship at Meta AI ([email protected]);
(2) Lambert Mathias, Meta AI ([email protected]);
(3) Rui Hou, Meta AI ([email protected]);
(4) Amjad Almahairi, Meta AI ([email protected]);
(5) Hao Ma, Meta AI ([email protected]);
(6) Jiawei Han, University of Illinois Urbana-Champaign ([email protected]);
(7) Wen-tau Yih, Meta AI ([email protected]);
(8) Madian Khabsa, Meta AI ([email protected]).
This paper is
[4] While these hyperparameters may lead to differences in trainable parameters, we keep them for analysis as they are used by the official implementation. Also, we observe that more trainable parameters do not guarantee better results.
[5] Tuning other hyperparameters like learning rate does not appear to alleviate the issue either.