

Table of Links
- Abstract and Introduction
- Related Work
- Experiments
- Discussion
- Limitations and Future Work
- Conclusion, Acknowledgments and Disclosure of Funding, and References
3.4 Comparison 3: Instruction-tuned vs. community-tuned variants
The final experiment conducted assessed whether this phenomenon could be seen in models finetuned by community developers on Hugging Face. We select models which have been additionally fine-tuned from instruction-tuned models, and compare results to the instruction-tuned model. Within this experiment we do not have complete visibility of the specific techniques used to fine-tune or the precise datasets which they were fine-tuned on.
Table 3 shows how toxicity rates vary amongst community-tuned models. Notably, the toxicity changes observed were not necessarily intuitive. For example, the uncensored variant of Llama-2-7B saw unsurprisingly high rates of toxicity (10%), but a similarly intentioned model for Gemma-2-2B (gemma-2-2b-it-abliterated) did not see comparably high toxicity rates (0.8%). This could be due to different datasets being used to uncensor (or “abliterate”) models, however this is not clear based on the model documentation available.
This experiment also included multiple models focused on multilingual generation, with fine-tuning data deriving from non-English languages. Figure 3 shows the bayesian analysis conducted for the overall toxicity rates for the Llama-3.1-8B variants, comparing the Chinese-Chat and SauerkrautLM8b-Instruct (tuned to improve German capabilities) models with the instruction-tuned variant. In Figure 3 we see directionally different patterns between the comparisons, but as the error bars for each analysis intersect with 0 we cannot conclude that there is a credible difference between the overall toxicity rates between the two models.
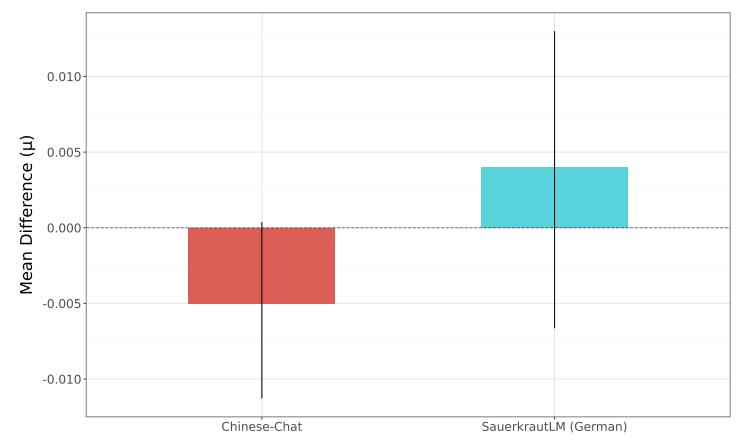
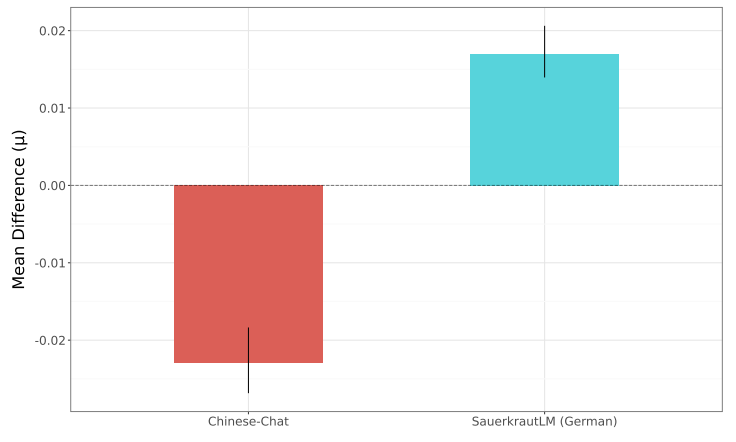
Figure 4 provides a different perspective, comparing the “severe toxicity” subset of data for the same models, where we see higher absolute differences between each variant. In this case, we see credible differences between both the Chinese-Chat and SauerkrautLM models compared with the Llama-3.1-8B-Instruct model. However, we see directional differences, with the German-focused fine-tuning from SauerkrautLM leading to fewer toxic outputs, whereas the Chinese-Chat model saw a greater number of toxic outputs.
These results underline how fine-tuning can impact the propensity of models to output toxic content, however this is not easily predictable, especially for users of models who do not have full information about fine-tuning parameters and data.
Authors:
(1) Will Hawkins, Oxford Internet Institute University of Oxford;
(2) Brent Mittelstadt, Oxford Internet Institute University of Oxford;
(3) Chris Russell, Oxford Internet Institute University of Oxford.
This paper is available on arxiv under CC 4.0 license.