

Table of Links
VI. Conclusions and References
V. RESULTS
We look at all the experiments done and describe the quantitative and qualitative detection results. The quantitative score compares the Average F1 score throughout the experiments. Thereafter, we look at the prediction result overlaid on the images for a visual analysis.
A. Quantitative Result
We show an aggregate plot in Fig. 10, with multiple axes for all the experiments run with their Average F1 score and HyperParameters for comparison. This also shows the progress we made as we continued to make changes to the Hyper-Parameters during optimization. The bars are the batch size and black dotted line is the learning rate variations during the experiments.
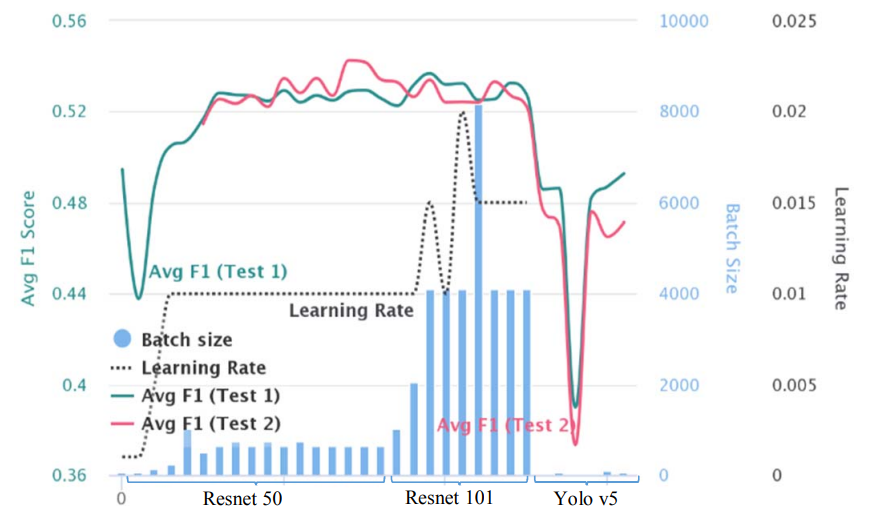
One observation in Avg F1 score evaluation (green for Test 1, red for Test 2) stood out is that, Resnet 101 [9] with high batch size does better on Test 1 evaluations but does not transfer to better results on Test 2 evaluation. Resnet 50 [9] with an order of magnitude lower batch size performs lower than the Test 1 evaluation of Resnet 101 but evaluates better than Resnet 101 on Test 2 F1 score. The depiction is for a generalized approach, but we have seen that we can always gain approximately 1.5% accuracy benefit by using a per country model approach.
B. Qualitative Results
We show the qualitative detection results visually overlaid on the provided Test images. We have used the models trained on (T+V) data composition for showcasing the results. Hence the images selected for this are from the 5% Test (T) data. The model itself is Faster R-CNN [4] with Resnet 50 [9] and FPN [5] backbone network. We will see few good and failed cases here
![Fig. 11. Successful results of detection on India_000052.jpg Test (T) data using Faster R-CNN [4] Resnet50+FPN [5] model. Trained on data from all countries. Multiple damage types like D20, D00 and D40 have been identified accurately. The model predicts small and medium bounding boxes with more than 70% classification accuracy. The lighting conditions are good and the textures in the captured image is clearly visible.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-rw133bw.png)
We show a detection output in Fig. 11, representing the case where all damages have been classified and localized.

The sample in Fig. 12, where the road is in damaged condition. Even though the lighting is good in one of the images, and the network has learnt small or medium damages, this texture spreads through the entire width of the road and may be difficult to learn due to lack of such annotations.
v

Kind of failures: In the Fig. 12 & Fig. 13, we have seen images with failed detections. The primary issues in images are due to low light conditions, camera mount positions, artifacts or shadows around objects of interest and inability to geo-fence a spatial range for detections which should be the capture region of interest and avoid looking far down the road.
VI. CONCLUSIONS
In this work, we experimented with few approaches and went with a single model trained on data across Czech, Japan and India over country specific detection model, due to its simplified deployment process. However, there is an argument against generalization considering training a model per country provides 1.5% improvement over generalized model. Segmentation of road surface as a pre-processing step did not benefit the object detection models considering the ground truth based localized area is not affected by the background features.
We compare the two-stage Faster R-CNN [4] with one-stage Yolov5 [15] detection model for evaluation of framework and observed significant improvement in average F1 score with two-stage network. In our experiments with backbone like FPN [5], Resnet 50 and Resnet 101 [9] in Faster R-CNN [4], Resnet 101 performs and fits the training data and Test 1 evaluation better when compared to its Resnet 50 counterpart which performs better on Test 2 evaluations.
Overall, we see that with larger network and high batch size the model fits the Test 1 evaluation set and otherwise on the Test 2 evaluation dataset. However, the challenge of the unbalanced and limited dataset prohibits the model from learning more. This is where Generative Adversarial Networks (GAN) [21] may be useful or a more structured approach of isolating damage features on road surface using pre-processing. The possibility of learning various parts of the damage may be useful in generation as well as reconstruction of such artifacts in captured images. A semantic segmentation dataset would have benefited by providing the precise structure and texture of the damage. It could have resulted in reducing false positives by better understanding of the damages. Depth information in the image or a spatial fencing in the image may help to limit the detections to damages observed closer to the camera’s point of view.
REFERENCES
[1] H. Maeda, Y. Sekimoto, T. Seto, T. Kashiyama, and H. Omata, “Road damage detection and classification using deep neural networks with smartphone images,” Computer-Aided Civil and Infrastructure Engineering, 2018.
[2] D. Arya, H. Maeda, S. K. Ghosh, D. Toshniwal, A. Mraz, T. Kashiyama, & Y. Sekimoto. “Transfer Learning-based Road Damage Detection for Multiple Countries”. arXiv preprint arXiv:2008.13101, 2020.
[3] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision (IJCV), vol. 115, no. 3, pp. 211–252, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, pp. 91–99, 2015.
[5] T.-Y. Lin, P. Dollar, R. B. Girshick, K. He, B. Hariharan, and S. J. ´ Belongie, “Feature pyramid networks for object detection.,” in CVPR, vol. 1, p. 4, 2017.
[6] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. ´ Microsoft COCO: Common objects in context. In European conference on computer vision, pages 740– 755. Springer, 2014.
[7] T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2380–7504, Venice, Italy, 22–29 October 2017.
[8] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask r-cnn,” IEEE International Conference on Computer Vision (ICCV), pp. 2980–2988, IEEE, 2017.
[9] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[10] S. Ioffe, and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448–456, 2015.
[11] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in The European Conference on Computer Vision (ECCV), 2016.
[12] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
[13] J. Redmon and A. Farhadi. YOLO9000: Better, faster, stronger. In CVPR, 2017.
[14] Y. Wu, A. Kirillov, F. Massa, W.-Y. Lo, and R. Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
[15] G. Jocher, A. Stoken, J. Borovec, NanoCode012, ChristopherSTAN, L. Changyu, Laughing, A. Hogan, lorenzomammana, tkianai, yxNONG, AlexWang1900, L. Diaconu, Marc, wanghaoyang0106, ml5ah, Doug, Hatovix, J. Poznanski, L. Y. , changyu98, P. Rai, R. Ferriday, T. Sullivan, W. Xinyu, YuriRibeiro, E. R. Claramunt, hopesala, pritul dave, and yzchen, “ultralytics/yolov5: v3.0,” aug 2020. [Online]. Available: https://doi.org/10.5281/zenodo.3983579.
[16] C.Y. Wang, H.Y. Mark Liao, Y.H. Wu, P.Y. Chen, J.W. Hsieh, I.H. Yeh. Cspnet: A new backbone that can enhance learning capability of cnn, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 390–391, 2020.
[17] K. He, X. Zhang, S. Ren, J. Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 37, 1904–1916. URL: https:// doi.org/10.1109/tpami.2015.2389824, doi:10.1109/tpami.2015. 2389824, 2015
[18] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff and H. Adam. EncoderDecoder with Atrous Separable Convolution for Semantic Image Segmentation. DeepLabV3Plus, ECCV, 2018.
[19] L. Liu, W. Ouyang, X. Wang et al. Deep Learning for Generic Object Detection: A Survey. International Journal Of Computer Vision 128, 261– 318. https://doi.org/10.1007/s11263-019-01247-4, 2020.
[20] S. Xie, R. Girshick, P. Dollár, Z. Tu, K. He. Aggregated Residual Transformations for Deep Neural Networks, arXiv preprint arXiv:1611.05431, 2016.
[21] I. J. Goodfellow, J. P.- Abadie, M. Mirza, B. Xu, D. W.-Farley, S. Ozair, A. Courville, Y. Bengio. Generative Adversarial Networks, NIPS, 2014
[22] JRA. Maintenance and repair guide book of the pavement 2013. Japan Road Association, 1st. edition, 2013.
[23] D. Arya, H. Maeda, S. K. Ghosh, D. Toshniwal, H. Omata, T. Kashiyama, & Y. Sekimoto. “Global Road Damage Detection: State-of-the-art Solutions”. arXiv:2011.08740, 2020.
Authors:
(1) Rahul Vishwakarma, Big Data Analytics & Solutions Lab, Hitachi America Ltd. Research & Development, Santa Clara, CA, USA ([email protected]);
(2) Ravigopal Vennelakanti, Big Data Analytics & Solutions Lab, Hitachi America Ltd. Research & Development, Santa Clara, CA, USA ([email protected]).
This paper is