

Authors:
(1) Yuwei Guo, The Chinese University of Hong Kong;
(2) Ceyuan Yang, Shanghai Artificial Intelligence Laboratory with Corresponding Author;
(3) Anyi Rao, Stanford University;
(4) Zhengyang Liang, Shanghai Artificial Intelligence Laboratory;
(5) Yaohui Wang, Shanghai Artificial Intelligence Laboratory;
(6) Yu Qiao, Shanghai Artificial Intelligence Laboratory;
(7) Maneesh Agrawala, Stanford University;
(8) Dahua Lin, Shanghai Artificial Intelligence Laboratory;
(9) Bo Dai, The Chinese University of Hong Kong and The Chinese University of Hong Kong.
Table of Links
- AnimateDiff
4.1 Alleviate Negative Effects from Training Data with Domain Adapter
4.2 Learn Motion Priors with Motion Module
4.3 Adapt to New Motion Patterns with MotionLora
5 Experiments and 5.1 Qualitative Results
8 Reproducibility Statement, Acknowledgement and References
5 EXPERIMENTS
We implement AnimateDiff upon Stable Diffusion V1.5 and train motion module using the WebVid10M (Bain et al., 2021) dataset. Detailed configurations can be found in supplementary materials.
5.1 QUALITATIVE RESULTS
Evaluate on community models. We evaluated the AnimateDiff with a diverse set of representative personalized T2Is collected from Civitai (2022). These personalized T2Is encompass a wide range of domains, thus serving as a comprehensive benchmark. Since personalized domains in these T2Is only respond to certain “trigger words”, we abstain from using common text prompts but refer to the model homepage to construct the evaluation prompts. In Fig. 4, we show eight qualitative results of AnimateDiff. Each sample corresponds to a distinct personalized T2I. In the second row of Figure 1, we present the outcomes obtained by integrating AnimateDiff with MotionLoRA to achieve shot type controls. The last two samples exhibit the composition capability of MotionLoRA, achieved by linearly combining the individually trained weights.
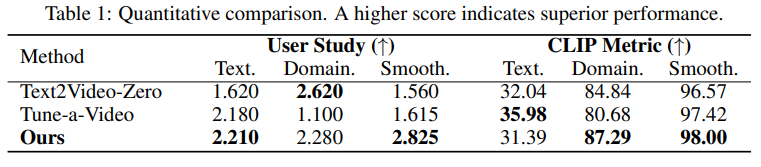
Compare with baselines. In the absence of existing methods specifically designed for animating personalized T2Is, we compare our method with two recent works in video generation that can be adapted for this task: 1) Text2Video-Zero (Khachatryan et al., 2023) and 2) Tune-a-Video (Wu 7 et al., 2023). We also compare AnimateDiff with two commercial tools: 3) Gen-2 (2023) for textto-video generation, and 4) Pika Labs (2023) for image animation. The results are shown in Fig. 5.

This paper is available on arxiv under CC BY 4.0 DEED license.