

Authors:
(1) Yuning Mao, University of Illinois Urbana-Champaign and the work was done during internship at Meta AI ([email protected]);
(2) Lambert Mathias, Meta AI ([email protected]);
(3) Rui Hou, Meta AI ([email protected]);
(4) Amjad Almahairi, Meta AI ([email protected]);
(5) Hao Ma, Meta AI ([email protected]);
(6) Jiawei Han, University of Illinois Urbana-Champaign ([email protected]);
(7) Wen-tau Yih, Meta AI ([email protected]);
(8) Madian Khabsa, Meta AI ([email protected]).
Table of Links
-
Experiments
Abstract
Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UNIPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup via gating mechanism. On the GLUE benchmark, UNIPELT consistently achieves 1~4% gains compared to the best individual PELT method that it incorporates and outperforms fine-tuning under different setups. Moreover, UNIPELT generally surpasses the upper bound that takes the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.[1]
1 Introduction
As pre-trained language models (PLMs) (Devlin et al., 2019) grow larger and larger (Brown et al., 2020), it becomes increasingly infeasible to perform conventional fine-tuning, where separate replicas of the model parameters are modified per single task. To solve the issue, there has recently been a surge of studies on parameter-efficient language model tuning (PELT), namely how to effectively tune the PLMs with fewer trainable parameters.
Existing PELT research generally aims at achieving performance comparable to fine-tuning with
as few trainable parameters as possible, which has seen significant progress – the task-specific trainable parameters used in most recent approaches (Lester et al., 2021; Guo et al., 2021) are almost negligible compared to the total parameters of the PLM (<1%). A more challenging yet less studied problem is whether one can achieve better performance than fine-tuning with fewer parameters. Recent studies (He et al., 2021; Li and Liang, 2021; Karimi Mahabadi et al., 2021b) find that some PELT methods are more effective than fine-tuning on certain tasks when training data is limited, possibly due to the reduced risk of overfitting. However, as found in our experiments (Table 1), different PELT methods exhibit diverse characteristics and perform rather differently on the same task, which makes it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and tasks (Ding and Hu, 2021).
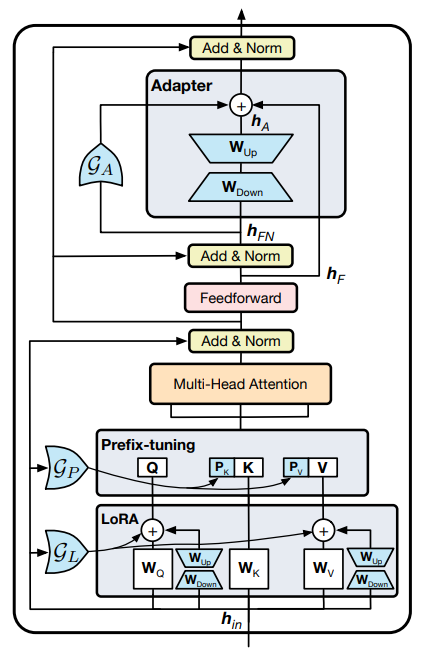
In light of the diverse performance of PELT methods and the cost of selecting the best method, we propose a unified PELT framework, named UNIPELT, which incorporates different PELT methods as submodules and learns to dynamically activate the (combination of) submodules that best suit the current data or task setup. As a result, model selection is no longer needed and consistently better performance is achieved under different setups. The activation of each submodule in UNIPELT is controlled by gating mechanism, which learns to favor (assign more weight to) the submodules that positively contribute to a given task. In addition, since the number of parameters introduced by each submodule is generally small, combining multiple methods leads to negligible losses in model efficiency.
We select four representative PELT methods for our study – adapter (Houlsby et al., 2019), prefixtuning (Li and Liang, 2021), LoRA (Hu et al., 2021), and BitFit (Ben Zaken et al., 2021), which largely cover the major categories of PELT methods. We perform two sets of analysis that carefully examines (i) the characteristics of individual PELT methods and (ii) their effectiveness when coordinated by UNIPELT under various setups.[2]
Extensive experiments on the GLUE benchmark (Wang et al., 2019), with 32 setups (8 tasks ×4 data sizes) and 1,000+ runs, not only reveal the diverse behavior of PELT methods, but also show that UNIPELT is more effective and robust than using each method alone in various task and data setups. Specifically, UNIPELT consistently improves the best submodule that it incorporates by 1~4 points and even outperforms fine-tuning, achieving the best average performance on the GLUE benchmark under different setups. Moreover, UNIPELT generally surpasses the upper bound that takes the best performance of all its submodules used individually on each task, which suggests that UNIPELT maintains (near) optimal performance under different setups. The fact that UNIPELT outperforms the upper bound also implies that a mixture of PELT methods involving different parts of the PLM architecture may be inherently more effective than individual methods.
Contributions. (1) We conduct a comprehensive study of representative PELT methods and carefully examine their differences and commonalities in terms of performance and characteristics. (2) We propose a unified PELT framework that can incorporate existing methods as submodules and automatically learn to activate the appropriate submodules for a given task. (3) Our proposed framework achieves better average performance than finetuning and the PELT methods that it incorporates under various setups, often performing the best and never the worst at per-task level, exhibiting superior effectiveness and robustness with negligible losses in model efficiency.
This paper is
[2] BitFit is not included in UNIPELT as it typically performs the worst in our preliminary experiments.